[모니터링의 새로운 미래 관측 가능성] Ch1. 관측 가능성의 개념과 방향성
관측 가능성 != 모니터링
관측 가능성이란?
관측 가능성과 모니터링은 유사한 점이 존재하지만 다른 개념이다. 관측 가능성은 내부 시스템에 대한 자세한 이해를 기반으로 미래에 발생할 이벤트를 예측하고, 예측을 바탕으로 IT 운영을 자동화하는 것이다. Elasticsearch, APM을 사용해 처리량과 지연시간을 모니터링하고, InfluxDB와 Telegraph, 다양한 에이전트를 통해 메트릭을 수집하고 측정하는 것이 관측 가능성을 구현해온 것이라 할 수 있다. 관측 가능성에서는 APM 대신 추적(tracing)이라 부르고, 계측과 텔레메트리라는 용어를 사용한다.
모니터링 대비 관측 가능성의 특징
1. 관측 가능성은 화이트박스 모니터링을 포함하며, 블랙박스 모니터링과 다르다. (블랙박스 모니터링은 상세한 디버깅 정보로의 활용이 어려움)
2. 관측 가능성은 애플리케이션 내부 상태를 디버깅할 수 있는 정보를 제공해 장애 발생 시 신속한 대응이 가능하다.
3. 관측 가능성은 결과를 이해하는 것을 넘어 원하는 계측을 추가할 수 있고, 향후 발생 가능성이 높은 장애 예측이 가능하다.
관측 가능성과 모니터링의 차이
- 관측 가능성
> 클라우드 네이티브처럼 분산된 시스템에서 발생하는 이벤트에 대한 통찰력, 로그 등을 결합해 서비스에 대한 context 정보를 제공하는 것이 목표
> 세부 시스템 내용을 포함해 디버깅에 더 적합
- 모니터링
> 블랙박스 모니터링을 기본으로 핵심 애플리케이션과 시스템 메트릭에 집중
> 적은 데이터를 수집하더라도 의미 있고 예측 가능한 결과를 도출하는 것에 집중
관측 가능성의 세 가지 구성 요소
1. 메트릭
- 일정 시간 동안 측정된 데이터를 집계하고 수치화한다. (ex - 큐의 대기 메시지 개수, 사용 중인 cpu와 메모리의 크기, 서비스에서 초당 처리하는 개수 등)
- 전체적인 시스템의 상태를 보고하는데 유용하다.
- 히스토그램이나 게이지 등 차트를 사용해 시각적으로 표현한다.
- 커스텀 메트릭 개발이 가능하지만 패키지 애플리케이션, 일부 레거시, 로드 밸런서 등이 커스텀 메트릭의 개발과 추가를 어렵게 해 솔루션을 구입한 벤더를 통해서만 커스텀 메트릭을 지원받을 수 있다.
- 프로메테우스(Prometheus)
2. 로그
- 애플리케이션의 에러와 경고를 확인하고, 문제에 대한 정확한 원인을 이해하기 위해 필요하다.
- JSON 형식이나 비구조적인 텍스트 형식으로 출력된다.
- 레거시 시스템일수록 메트릭보다 로그를 사용해 시스템 내부를 이해하고 문제를 해결하는 편이다.
- 오픈텔레메트리(OpenTelemetry)
3. 추적
- 마이크로서비스가 시스템을 경유하며 트랜잭션을 처리하는 과정에서 발생하는 세부적인 정보를 보여준다.
- 트랜잭션을 처리하는 과정에서 발생하는 대기시간과 지연시간, 병목현상이나 에러를 일으키는 원인을 context, 로그, 태그 등의 메타 데이터에 출력한다.
- 예거(Jaeger)
메트릭
메트릭은 가용성을 측정하는 주요 관찰 수단이며 SLI(Service Level Indicator, 서비스 수준 지표)를 측정하는 지표이다. SLI는 SLO(Service Level Objective, 서비스 수준 목표)라 불리는 임계 기준을 달성해야 한다. SLO는 SLA(Service Level Agreement, 서비스 수준 협약)에 명시된 제공 수준보다 제한적이거나 보수적인 추정치이다.
골든 시그널
구글의 SRE팀에서는 메트릭을 수집할 때, 4가지의 골든 시그널에 집중한다. 이 4가지는 지연, 에러, 트래픽, 포화이다.
1. 지연
- 시계열, 히트맵, 히스토그램 차트로 지연을 시각화한다.
- 아래 그림은 그라파나의 히스토그램을 사용해 지연시간의 분포를 시각화한 것이고, 다양한 유형의 PromQL(Prometheus Query)로 지연을 계산할 수 있다.
- 지연은 잠재적인 장애를 예측할 수 있는 신호로, 서비스 요청 후 완료까지 걸리는 시간을 측정한다.
- 1초의 지연을 포함하는 정상 응답 != 60초의 지연을 포함하는 정상 응답
-> 60초 지연은 에러로 판단하거나 타임아웃으로 처리하는 것이 현명하다.

2. 에러
- 에러는 문제점과 에러 내용을 직접적으로 출력해준다.
- 에러는 정상(normal), 대기(pending, 에러 처음 발견 시), 파이어링(firing, 에러가 계속 활성 상태를 유지할 시)의 세 가지 상태가 있다.

- 에러 SLO를 계산하는 프로메테우스 PromQL
sum(rate(hotrod_frontend_http_requests_total{status_code="4xx"}[{{.window}}]))
/
total_query: sum(rate(hotrod_frontend_http_requests_total[{{.window}}]))
3. 트래픽
- 발생하는 요청의 양
- 트래픽의 양이 급격히 많아지거나 임계치를 초과하거나 포화 상태가 되면 지연과 에러가 발생하며 최종적으로 장애를 야기시킨다.
- 골든 시그널의 원칙은 트래픽이 증가해도 지연과 에러를 최소화하고 최종적으로 장애에 이르지 않도록 설계하는 것이다.

- 네트워크 트래픽을 계산하는 프로메테우스 PromQL
irate(node_network_receive_packets_total{instance="$node",job="$job"}[$__rate_interval])
4. 포화
- 리소스가 '현재 얼마나 채워졌는지'와 '얼마나 가득 채울 수 있는지'를 나타내는 것으로, 전체 총대역폭과 처리 가능한 트래픽에 대비해 현재 트래픽 혹은 대역폭이 어느 정도인지 이해할 수 있는 지표다.
- 포화를 통해 트래픽이 증가했을 경우 이용 가능한 자원 총사용률을 예측할 수 있다.
- CPU 사용률 SLO를 계산하는 프로메테우스 PromQL
(
instance:node_cpu_utilization:rate1m{job="node"}
*
instance:node_num_cpu:sum{job="node"}
)
/ scalar(sum(instance:node_num_cpu:sum{job="node}))
- CPU 포화율 SLO를 계산하는 프로메테우스 PromQL
instance:node_load1_per_cpu:ratio{job="node"}
/ scalar(count(instance:node_load1_per_cpu:ratio{job="node"}))
SLO 대시보드 개발 시 참고할 사항
- 필수적인 SLO는 에러율, 지연시간, 가용성 등이다.
- 오류 예산과 번 레이트를 다양한 윈도(분, 시, 일, 월 등의 주기)에 따라 알람과 연계해 출력해야 한다.
- 프로메테우스 레코딩 규칙과 알람 규칙으로 구현할 수 있고, 이러한 규칙은 자동 생성 방식을 선호한다.
- 쿠버네티스 API 서버와 코어 DNS, AWS 클라우드 워치, 데이터 독 등 다양한 데이터로부터 데이터 수집이 가능하다.
메트릭 유형
일반적으로 메트릭은 카운터, 게이지, 요약, 히스토그램의 네 가지 유형이 있다.
1. 카운터
- 모니터링하는 이벤트의 누적 개수 혹은 크기
- rate함수와 이벤트 추적하는 데 사용한다.
- 초당 요청 개수, 초당 처리 개수
2. 게이지
- 카운터와 달리 증감의 임의의 값을 나타내는 메트릭이다.
- 현재 상태를 표현한다.
- DB에 연결된 커넥션 개수, 현재 동작하는 스레드 개수, 사용률
3. 요약
- 응답의 크기와 대기시간을 추척하는데 사용한다.
- 특정 이벤트의 합계와 카운트를 모두 제공한다.
- 범위와 분포에 관계없이 정확한 백분위수가 필요하면 요약이 적합하다.
4. 히스토그램
- 시간 경과에 따른 추세와 데이터가 단일 범주에서 어떻게 분포되어 있는지를 나타낸다.
- 히스토그램은 분위수를 사용하는데, 분위수는 오름차순(or 내림차순)으로 정렬되어 있는 전체 자료를 특정 개수로 나눌 때 기준이 되는 수이다.
시계열 데이터


로키(Loki)는 히스토그램과 유사한 차트를 사용하며 특정 시간 동안 분포를 이해라 수 있는 뿐만 아니라 추적의 간트 화면으로 전환할 수 있다. 프로메테우스 exemplar는 추적에 대한 근사치를 시계열로 표현한다.

위 그림에서는 특별한 구성 없이 간단한 쿼리로 하나의 화면에서 실시간으로 지연시간, 에러를 확인할 수 있다. 상관관계는 시스템의 복잡성을 낮추고 이해도를 높여 복잡한 문제를 신속히 해결하는데 도움이 된다.
프로메테우스의 히스토그램

히스토그램을 사용해 요청 지속 시간과 응답 크기를 구할 수 있다. 다음은 5분간의 요청 지속 시간의 평균을 계산하는 식이다.
rate(tns_request_duration_seconds_sum[5m])
/
rate(tns_request_duration_seconds_count[5m])
다음과 같은 히스토그램 요구 사항이 있을 때 프로메테우스 표현식으로 나타내보자
SLO는 요청의 95%를 0.1초 이내에 처리한다. 이 수치가 0.95 미만으로 내려가면 알람을 생성한다.
sum(rate(tns_request_duration_seconds_bucket{le="0.1"}[5m])) by (job)
/
sum(rate(tns_request_duration_seconds_count[5m])) by (job)
메트릭 관리 방안
실제 운영 환경에서는 기본 메트릭만으로 부족해 복잡한 커스텀 메트릭을 사용해 쿠버네티스 오토스케일링 또한 수행할 수 있다.
프로메테우스 클라이언트 API를 사용해 rpc_durations_seconds 메트릭과 이그젬플러를 개발한다. 다음은 지연시간 분포를 보이는 3개의 RPC서비스(Uniform, Normal, Exponential)의 히스토그램을 데모하는 소스이다.
func NewMetrics(reg prometheus.Registerer, normMean, normDomain float64) *metrics {
m := &metrics{
rpcDurations: prometheus.NewSummaryVec(
prometheus.SummaryOpts{
Name:"rpc_durations_seconds",
Help:"RPC latency distributions.",
Objectives: map[float64]float64{0.5:0.05, 0.9:0.01, 0.99:0.001},
},
string{"service"},
),
rpcDurationsHistrogram: protheus.NewHistogram(prometheus.HistogramOpts{
Name:"rpc_durations_histogram_seconds",
Help:"RPC latency distributions.",
Buckets: prometheus.LinearBuckets(normMean-5*normDomain, .5*normDomain, 20),
NativeHistogramBucketFactor: 1.1,
}),
}
reg.MustRegister(m.rpcDurations)
reg.MustRegister(m.rpcDurationsHistogram)
return m
}
이그젬플러를 출력하기 위한 명령어는 curl -H 'Accept: application/openmetrics-text' localhost:8080/metrics이다. 이 명령어를 사용하면 오픈 메트릭 형식으로 메트릭을 출력할 수 있다. 포스트맨을 사용해 오픈메트릭을 출력하면 아래와 같다.

로그
로그 관리의 목적인 시스템에 분산된 로그를 한 곳에 저장해 다루기 쉽게 하는 것이다. 로그를 수집하고 관리할 수 있는 인프라와 시스템을 구축했다면, 그 다음에는 다양한 로그 유형을 표준화하는 작업이 필요하다. 분산 시스템에서 데이터를 수집하는 데에는 어려움이 있다. 실행 중인 파드가 교체된 후 살아남은 로그 데이터가 있더라도 시스템에서 요청을 추적하기는 쉽지 않다. 따라서 시스템에서 일어나는 일을 기록하는 더 나은 방법이 필요하다.
급격하게 증가하는 로그 데이터를 처리하기 위해 로그 관리 시스템은 동적이고 수평 확장을 지원해야 한다. 이를 위해서는 가상머신, 도커, 쿠버네티스 파드 등 다양한 런타임 환경에서 동일한 방식으로 로그 데이터를 수집해야 한다. 또한 클라우드 네이티브는 멀티 테넌트를 지원해야 한다. 즉 단일한 록 시스템을 사용해 다양한 조직과 서비스에서 생성하는 로그 데이터를 수집하고 중앙 집중 관리를 해야 한다.
타임스탬프, 식별자 소스, 레벨 또는 카테고리는 로그 파일에 명시되어야 하는 정보이다. 또한 로그 엔트리를 생성할 때 사람이 읽을 수 있는 형태면서 머신에 의해 쉽게 파싱되는 것이어야 한다.
로그 표준화
로그 관리 시스템에서 입력되는 키와 로그 파일의 키가 일치하도록 표준화를 진행하는 건 중요하다. 오픈텔레메트리의 로깅 신호는 로깅 인터페이스 표준화와 관련이 없어 로깅 파이프라인에 표준화를 함께 구성해야 한다.
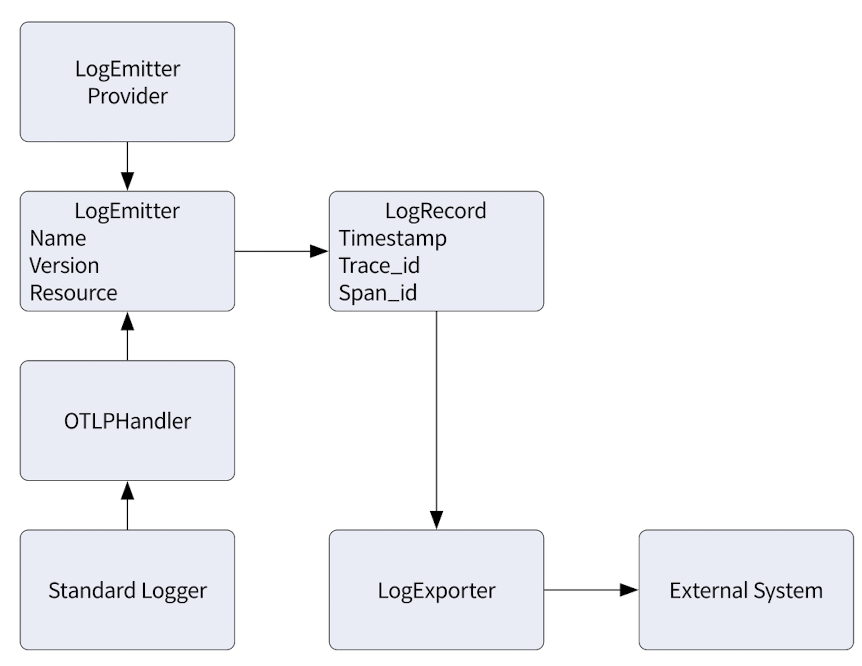
위의 그림은 하나 이상의 로그 이미터를 인스턴스화하는 매커니즘을 제공하는 LogEmitterProvider, LogRecord 데이터를 생성하는 LogEmitter, 로그 레코드를 사용하고 데이터를 백엔드로 보내는 LogExporter가 있다.
Go의 표준 라이브러리 logger를 사용해 로그를 표준화할 수 있다.
package main
import (
"time"
"go.uber.org/zap"
)
func main() {
logger, _ := zap.NewProduction()
defet logger.Sync()
logger = logger.Named("my-app")
logger.Info
("failed to fetch URL",
zap.String("url", "https://github.com"),
zap.Int("attempt", 3),
zap.Duration("backoff", time.Second),
)
}
로그 관리를 요약하면 각 시스템에 분산되어 있는 로그를 어떻게 수집하고 통합, 관리할 것인지 먼저 정해야 한다. 그 후 각 애플리케이션은 다른 로그 형태를 가지고 있기 때문에 어떻게 로그 형식을 표준화하고 단일화할 것인지 결정해야 한다. 구조적 로그는 json을 사용하는 것이 일반적이고, 레거시 시스템은 비구조적이고 단순한 텍스트 파일 형태로 구성된다.
추적
추적과 관련된 용어를 먼저 정리하자.
스팬
- 전반적인 수행 시간 정보뿐 아니라 각기 하위 동작의 시작과 소요 시간 정보를 알 수 있다.
- 동작 정보, 타임라인과 부모 스팬과의 의존성을 모두 포함하는 수행 시간을 담고 있다.
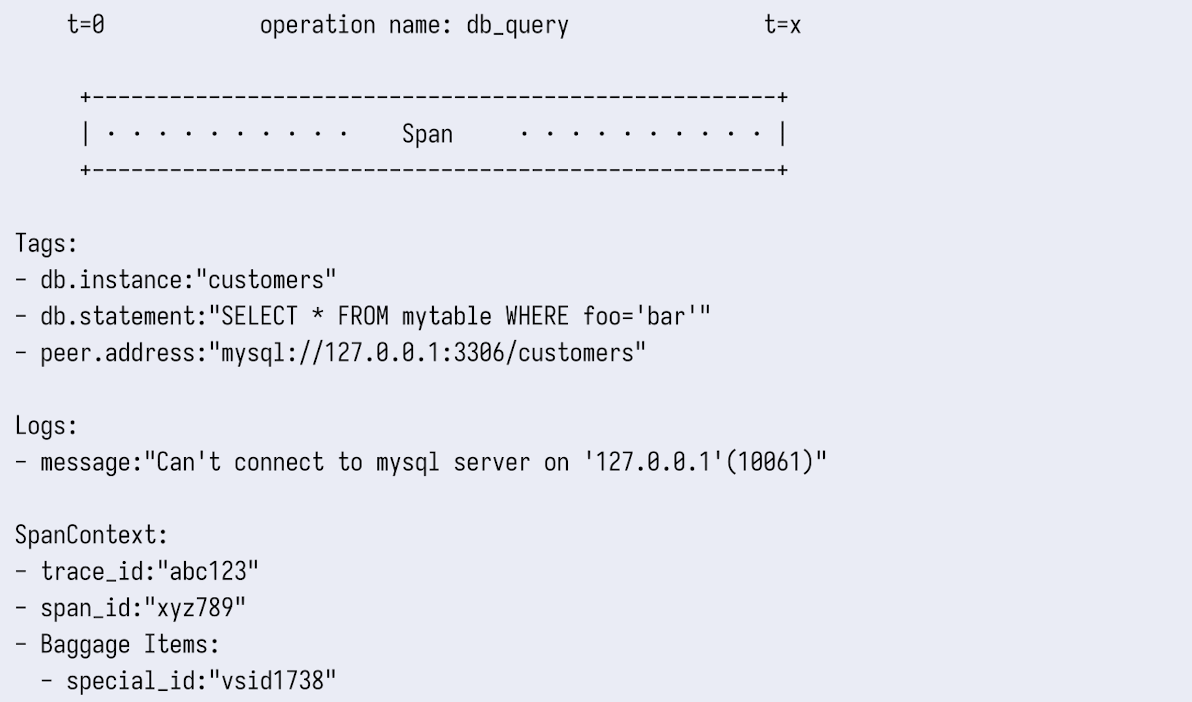
스팬은 태그, 로그, 스팬 콘텍스트, 배기지 정보를 포함한다.
스팬 콘텍스트
- 새로운 스팬을 생성하려면 스팬 콘텍스트에서 정보를 확인한다.
- 스팬 콘텍스트로 표현된 메타데이터를 쓸 수 있는 Inject와 읽을 수 있는 Extract 메서드를 제공한다.
- 즉, 주입과 추출을 통해 헤더에 전달되고, 전달딘 스팬 콘텍스트에서 추출한 스팬 정보로 새로운 지식 스팬 생성이 가능하다.
스팬 레퍼런스
- 두 스팬 사이의 인과관게이다.
- 스팬들이 동일한 추적에 속한다는 것을 추적자가 알 수 있게 한다.
추적 데모
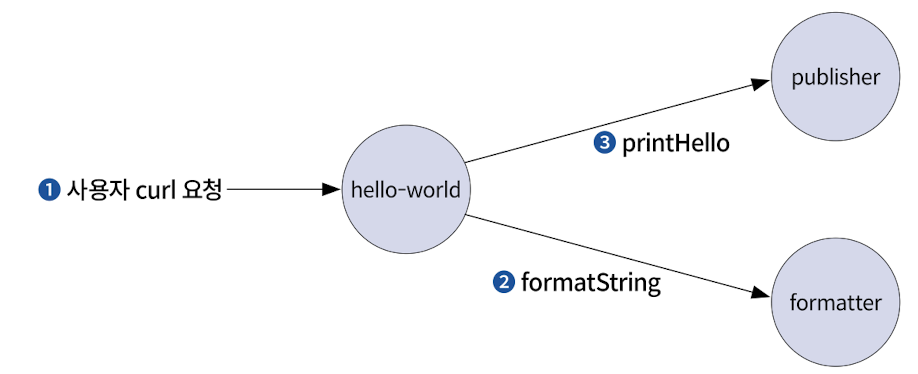
데모의 처리 순서는 다음과 같다. 1) curl로 hello-world 서비스를 호출한다. 2) hello-world 서비스는 formatter 서비스를 호출한다. 3) hello-world 서비스는 publisher 서비스를 호출한다.
메인 애플리케이션인 hello.go는 formatter와 publisher 서비스에 각각 HTTP 호출을 수행하는 formatString, printHello라는 2개의 로컬 함수를 갖는다.
1개의 스팬으로 구성된 추적을 생성하는 프로그램을 작성한다. 이 스팬은 2개의 옵션을 결합해 출력 문자열을 포맷팅하고 출력한다.
span := tracer.StartSpan("say-hello")
span.SetTag("hello-to", helloTo)
defer span.Finish()
helloStr := formatString(span, helloTo)
printHello(span, helloStr)
여기서 3개의 스팬을 얻었다?
원하는 결과는 main에서 시작된 루트 스팬에 대한 2개의 새로운 스팬 사이의 레퍼런스를 설정하는 것이니까 StartSpan 함수에 추가 옵션을 전달한다.
func formatString(rootSpan opentracing.Span, helloTo string) string{
span := rootSpan.Tracer().StartSpan("formatString")
defer span.Finish()
helloStr := fmt.Sprintf("Hello, %s!", helloTo)
span.LogFields(
log.String("event","string-format"),
log.String("value", helloStr),
)
return helloStr
}
func printHello(rootSpan opentracing.Span, helloStr string) {
span := rootSpan.Tracer().StartSpan("printHello")
defer span.Finish()
pritln(helloStr)
span.LogKV("event", "println")
}
(1) 프로세스 간 콘텍스트 전파
hello-world 서비스는 1개의 추적에서 2개의 스팬을 얻는다. 그리고 2개의 마이크로서비스가 더 있으므로 프로세스 간 RPC 호출을 위한 추적을 구현해야 한다. 이를 위해서는 스팬 콘텍스트를 전파하기 위해 오픈트레이신 API의 Inject, Extract 두 가지 메서드를 사용한다.
가장 먼저 트레이서에서 Inject를 호출한다.

tracer.Extract를 통해 수신되는 요청에서 스팬 콘텍스트를 추출한다.

(2) 배기지
지금까지 스팬 콘텍스트를 다른 애플리케이션 사이에 전파하는 것을 구현했다. 배기지는 메타데이터를 트랜잭션과 연결하고 어디서나 메타데이터를 사용할 수 있도록 범용적인 콘텍스트 전파를 구현하는 것이다.

hello.go를 다음과 같이 수정했다. 두 번째 명령 줄 인수를 greeting 키 아래의 배기지에 저장한다.

또한 포맷터에서 배기지를 조회할 수 있도록 포맷터의 http 헤더에 다음 로직을 추가했다.
이렇게 코드를 작성하면 실행 순서는 다음과 같다.
1. 예거 추적을 시작한다.
2. formatter 서비스를 시작한다.
3. publisher 서비스를 시작한다.
4. hello-world 서비스를 시작한다.
5. curl로 hello-world 서비스를 호출한다.
코드를 빌드하고 예거를 시작하면 아래와 같은 화면을 볼 수 있다.

위의 예거 화면은 추적 개수를 보여주는데 hello-world, formatter, publisher 3가지를 보여준다. formatter와 publisher는 각각 1개, hello-world는 3개의 스팬을 가지고 있다.

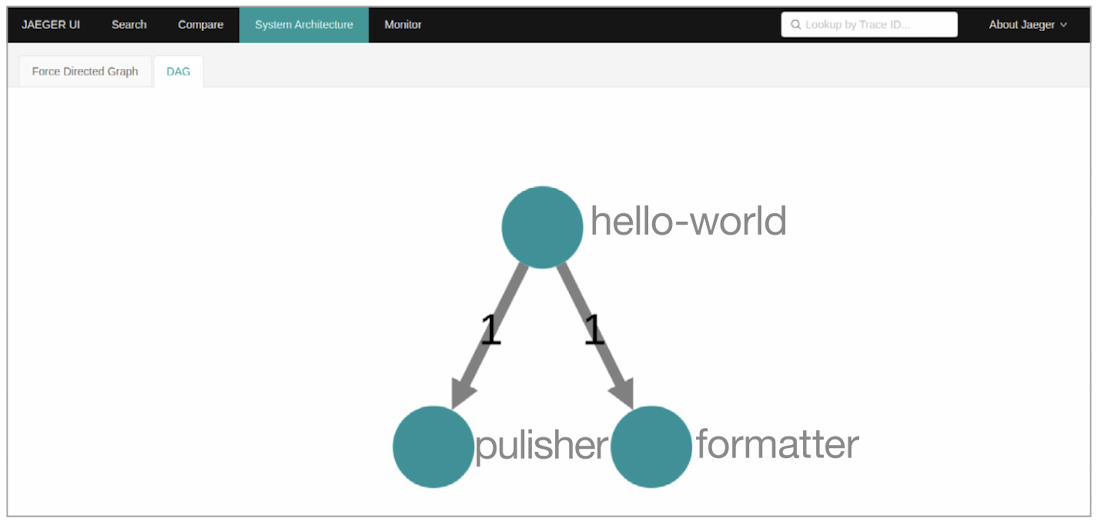
상관관계
이 책에서는 다섯 가지 신호에 대해 설명하고 이들 간의 상관관계를 정의한다. 로그, 메트릭, 추적 외에 다른 중요한 신호는 프로파일과 RUM이다.

- 로그와 추적
> 로그 파일에는 추적을 식별하는 추적 ID를 추가할 수 있다.
> 스팬 콘텍스트 내 메카데이터에는 로그 파일명을 추가할 수 있다.
> 특정 로그 파일을 선택하면 추적 ID를 출력한다.
> 추적 화면에서 추적 ID를 선택하면 해당 추적 ID를 포함하는 로그 파일로 이동할 수 있다.
- 추적과 메트릭
> 이그젬플러를 사용해 메트릭에서 추적으로 상관관계를 정의할 수 있는데, 이그젬플러는 프로메테우스 내부 저장소이고, 이 저장소에 추적을 저장한다.
> 템포는 메트릭 제너레이터, 예거는 메트릭 스토리지라는 기능으로 추적에서 메트릭 상관관계를 정의할 수 있다.
- 메트릭과 로그
> 메트릭과 로그를 나타내는 특별한 기술이 없다.
- 프로파일과 RUM
> 프로파일은 하위 수준의 상세한 디버깅 정보를 제공한다.
> RUM은 js로 개발된 frontend의 문제점을 분석하는데 유용하다.
관측 가능성 목표
책에서 단계적으로 구축할 클라우드 네이티브 관측 가능성 레퍼런스 아키텍처이다.

- 멀티 클러스터와 멀티 테넌트 운영
- 대용량 시계열 빅데이터 수집/관리
- 로그, 메트릭, 추적의 상호관계 확립
- 트래픽의 관리와 가시성 확보
- 관측 가능성, 가시성 정보를 통합
- 운영 비용 절감과 기술 내재화
- 개발과 운영을 위한 베스트 프랙티스 제공
- 운영의 자동화와 AIOps 고도화
- 근본 원인 분석
관측 가능성 오픈소스
- 오픈텔레메트리: 계측을 위한 표준화된 도구, API, SDK의 모음이다.
- 로키: 그라파나의 로그 관리 시스템이다.
- 그라파나 미미르: 프로메테우스용 오픈소스, 수평 확장성, 고가용성, 멀티 테넌트, 장기 저장소이다.
- 타노스: 프로메테우스를 통합할 수 있는 글로벌 뷰를 제공한다. 대용량 메트릭 관리를 위한 장기 저장소를 제공한다.
- 예거: 분산 콘텍스트 전파를 포함한 마이크로서비스 기반 분산 시스템 모니터링과 추적에 사용한다. 백엔드 저장소와 통합이 가능하다.
- 그라파나 템포: 그라파나의 오픈소스 추적 솔루션으로, 멀티 테넌트, 객체 스토리지 저장소, 메트릭 자동 생성 등을 쉽게 구현할 수 있다.