[CKA] Udemy CKA 강의 Scheduling02 - Resource Requirements and Limits, DaemonSets, Static Pods, Multiple Schedulers
Resource Requirements and Limits
Resource Requests
request는 k8s가 컨테이너에 대해 보장하는 최소한의 자원이다. 컨테이너가 스케줄될 때, k8s는 해당 자원을 제공할 수 있는 노드를 선택하기 위해 request를 사용한다. 요청된 자원을 제공할 수 있는 노드가 없다면 파드는 해당 노드에서 실행되지 않는다. request를 설정하기 위해 아래 yaml 처럼 작성할 수 있다.
#pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: web
labels:
name: web
spec:
containers:
- name: web
image: web
ports:
- containerPort: 8080
resources:
requests:
memory: "4Gi"
cpu: 2이 예시에서 컨테이너는 4Gi의 메모리와 2코어 cpu를 요청합니다.
CPU
1 cpu는 100m으로 표현될 수 있고, m은 밀리를 뜻한다. 1m까지는 가능하지만 그 이하는 불가능하다. 1cpu는 aws vcpu와 같고, gcp와 azure의 1core와 같다.
Memory
1Gi(Gibibyte) = 1,073,741,824 bytes
1Mi(Mebibyte) = 1,048,576 bytes
1Ki(Kibibyte) = 1,024 bytes
Resource Limits
limit는 컨테이너가 사용할 수 있는 최대 자원이다. 컨테이너가 한계를 초과하려 하면 k8s는 cpu 사용을 제한하거나 메모리를 초과하면 컨테이너를 종료할 수 있다. 자원 한계는 컨테이너가 너무 많은 자원을 사용하는 것을 방지해 같은 노드에서 실행되는 다른 컨테이너에 영향을 미치지 않도록 한다. 아래 yaml과 같이 한계를 설정할 수 있다.
#pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: web
labels:
name: web
spec:
containers:
- name: web
image: web
ports:
- containerPort: 8080
resources:
requests:
memory: "1Gi"
cpu: 1
limits:
memory: "2Gi"
cpu:2
만약 limit를 초과한다면?
cpu의 경우에는 시스템이 cpu를 조절해 지정된 한도를 넘지 않도록 한다. 하지만 memory는 그렇지 않아 컨테이너가 지정된 memory보다 많은 memory를 소모하면 해당 파드는 OOM(Out Of Memory) 에러로 terminate된다.
LimitRange를 사용하자!
#limit-range-cpu.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-costraint
spec:
limits:
- default:
cpu: 500m
defaultRequest:
cpu: 500m
max:
cpu: "1"
min:
cpu: 100m
type: Container제한 범위는 기본 값을 정의하는데 도움을 준다. 파드 yaml의 요청이나 특정 한도 없이 생성된 컨테이너에 대한 설정이다.
#limit-range-memory.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: memory-resource-costraint
spec:
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container파드가 만들어질 때만 이 제한이 적용되어 파드가 생성된 후에 제한 범위를 만들거나 변경해도 기존 파드에는 영향이 없다는 것을 명심하자.
Resource Quotas
리소스 쿼터는 특정 네임스페이스에서 사용 가능한 자원의 상한선을 정의하는 매커니즘이다. 이를 통해 워크로드 간에 자원을 공정히 분배할 수 있으며, 클러스터의 과도한 자원 사용을 방지할 수 있다.
리소스 쿼터의 목적은 다음과 같다.
1. 공정한 자원 분배: 클러스터 내 여러 네임스페이스가 자원을 균등히 사용할 수 있도록 보장
2. 과도한 사용 방지: 특정 네임스페이스가 클러스터의 자원을 독점하지 않도록 제한
3. 자원 관리 효율성: 관리자가 클러스터의 자원을 보다 체계적으로 관리할 수 있도록 도움
리소스 쿼터를 통해 제한할 수 있는 항목은 4가지가 있다. cpu와 메모리, 파드/서비스/레플리카셋/pvc 등의 오브젝트 수, 스토리지, configmap 및 secret이 있다. 이 중 cpu와 메모리를 제한하는 yaml은 아래와 같다.
#resource-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: my-resource-quota
spec:
hard:
requests.cpu: 4
requests.memory: 4Gi
limits.cpu: 10
limits.memory: 10Gi
💡 Resource Quota와 LimitRange의 차이
- Resource Quota: 네임스페이스 전체 자원 사용량에 대한 총량 제한을 설정
- LimitRange: 네임스페이스 내 개별 파드 또는 컨테이너의 자원 요청, 한계 기본값을 설정
실습
1) k describe po rabbit
2) k delete po rabbit
3,4) k describe po elephant
5,6) k get po elephant -o yaml > pod.yaml && yaml의 limits를 20Mi로 변경 && k delete po elephant && k create -f pod.yaml
7) k delete po elephant
Daemon Sets
데몬셋은 레플리카셋과 비슷한 것이다. 여러 개의 인스턴스 파드를 배포하도록 도와준다. 하지만 클러스터 노드마다 파드를 하나씩 실행한다. 클러스터에 새 노드가 추가될 때마다 파드 복제본이 자동으로 해당 노드에 추가되고, 노드가 제거되면 파드는 자동으로 제거된다. 즉, 데몬셋은 파드의 복사본을 클러스터의 모든 노드에 항상 존재하게 만든다.
// daemon-set-definition.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: monitoring-daemon
spec:
matchLabels:
app: monitoring-agent
template:
metadata:
labels:
app: monitoring-agent
spec:
containers:
- name: monitoring-agent
image: monitoring-agent데몬셋 yaml 파일은 rs yaml 파일과 비슷하다.
- 명령어
- k create -f daemon-set-definition.yaml
- k get daemonsets
- k describe daemonsets monitoring-daemon
- 더 자세하게 보기 위한 명령어
실습
1,2,3) k get daemonset -A
4) k describe ds kube-proxy -n kube-system
5) k describe ds kube-flannel-ds -n kube-system
6) k create deployment elasticsearch -n kube-system --image=<주어진거> --dry-run=client -o yaml > fluentd.yaml
-> kind: DamonSet으로 변경, 필요없는거 삭제
-> k create -f fluentd.yaml
Static Pods
kubelet은 노드를 독립적으로 관리할 수 있다. 워커노드에는 컨테이너를 작동할 컨테이너 런타임인 도커도 있다. 하지만 kube apiserver 같은 쿠버네티스 관련된 건 없다. kubelet이 아는 건 파드를 만드는 것 뿐이고, 파드의 상세 정보를 제공할 apiserver가 없다. 그렇다면 어떻게 kube apiserver 없이 kubelet에 파드 yaml을 전달할 수 있을까?

서버 디렉토리를 통해 파드 정의 파일을 읽을 수 있다. 서버 디렉토리에 파드 yaml을 저장하면, kubelet이 주기적으로 이 디렉터리에 파일을 확인하고, 호스트에 파드를 만든다. pod의 manifest 파일이 조금이라도 변경되면 kubelet은 파드를 다시 만든다. 이 디렉터리에서 파일을 삭제하면 파드는 자동적으로 삭제된다. 이렇게 kubelet이 스스로 만든 파드는 apiserver의 간섭이나 나머지 쿠버네티스 클러스터 구성 요소의 간섭이 없는 정적 파드가 된다.
Static Pods vs DaemonSets
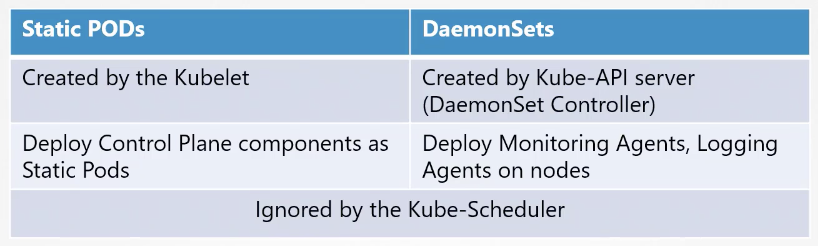
- 데몬셋은 클러스터 내 모든 노드에서 응용 프로그램 인스턴스가 사용 가능
- 정적 파드는 쿠블렛이 직접 만듦
- 공통점은 kube-scheduler를 무시한다는 점인데 큐브-스케줄러는 파드에 아무 영향을 못 줌
실습
1) k get po -A -> 파드의 이름을 보고 마지막에 노드 이름(ex. kube-apiserver-controlplane(o), kube-proxy-c5zpk(x))이 들어간 파드가 정적 파드임 || 아니면 파드 하나씩 보는 방법이 있음 ownerReference가 Node여야함 k get po kube-apiserver-controlplane -n kube-system -o yaml
2,3,4) k get po -A
5) cat /var/lib/kubelet/config.yaml
6) ls /etc/kubernetes/manifests
7) cat /etc/kubernetes/manifests/kube-apiserver.yaml
8) k run static-busybox --image=busybox --dry-run=client -o yaml --command -- sleep 1000 > static-bysubox.yaml && cp static-busybox.yaml /etc/kubernetes/manifests
9) vi /etc/kubernetes/manifests/static-busybox.yaml
10) static pod는 삭제해도 kubelet에서 계속 생성하기 때문에 static pod의 Manifest가 있는 Node에 가서 삭제해야함
ssh <ip> && cat /var/lib/kubelet/config.yaml && cd /etc/just-to-mess-with-you && rm greenbox.yaml
Mutiple Scheduler
이번에는 다수의 스케줄러를 배포하는 방법을 공부할 것이다. 쿠버네티스는 노드에 걸쳐 파드를 고르게 분배하는 알고리즘을 가지고 있는 걸 배웠고, 이 종류로는 taint, toleration, node affinity 등이 있다는 것도 배웠다.
쿠버네티스는 확장이 아주 쉬워 쿠버네티스 스케줄러 프로그램을 작성해 기본 스케줄러로 패키지하거나 쿠버네티스 클러스터에서 추가 스케줄러로 배포할 수 있다. 하지만 일부 특정 응용 프로그램은 우리가 작성한 사용자 지정 스케줄러를 사용할 수 있다.
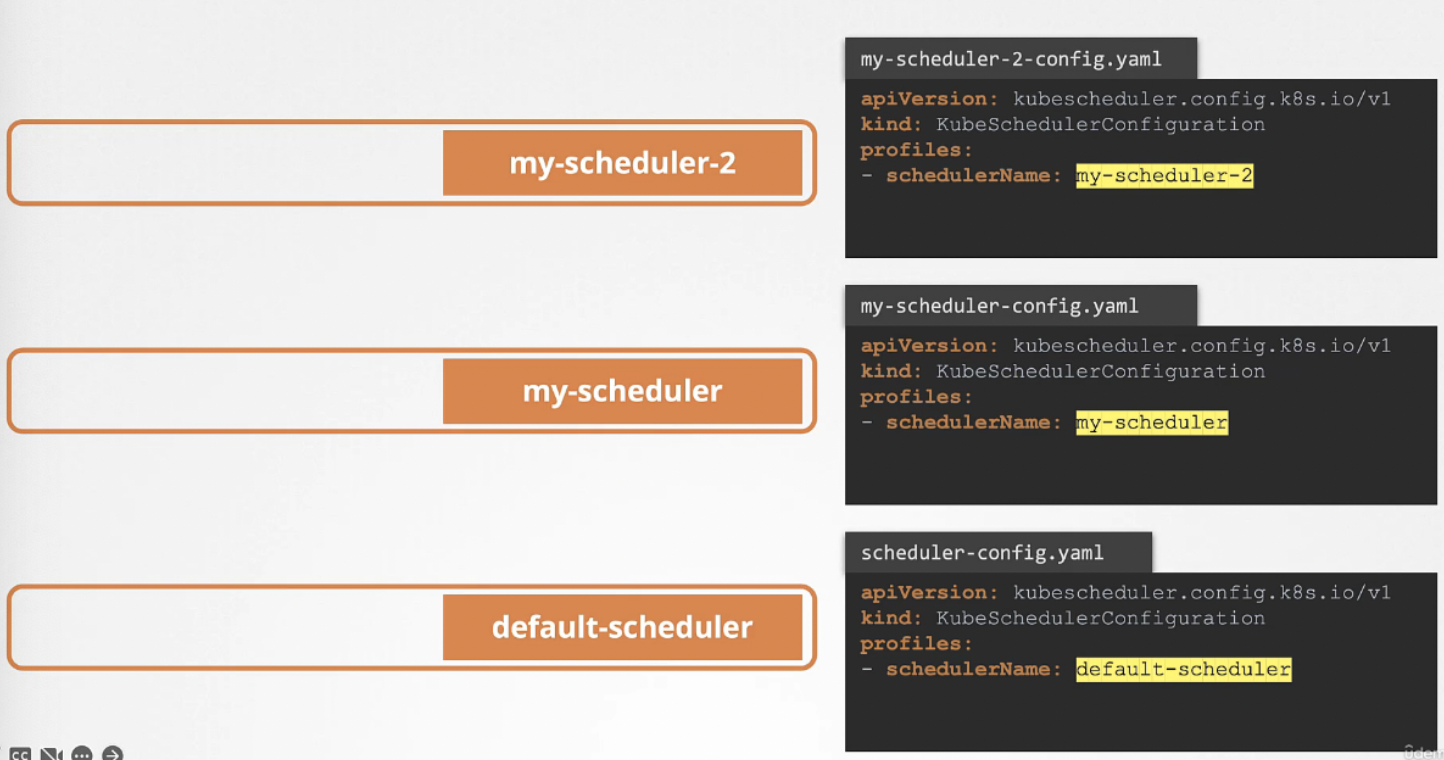
쿠버네티스 클러스터는 한 번에 여러 스케줄러를 가질 수 있는데, 파드를 만들거나 배치할 때 쿠버네티스에게 특정 스케줄러가 파드를 지정하도록 지시할 수 있다. 스케줄러가 여러 개일 경우 반드시 고유한 이름을 가져야 하고, 스케줄러 config yaml을 사용해 각 스케줄러의 이름을 설정할 수 있다. 이때 이름을 지정하지 않으면 스케줄러의 이름은 default-scheduler가 된다.
추가적인 스케줄러 배포하는 방법
kube-scheduler 바이너리를 다운로드 받아 여러 옵션과 함께 kube-scheduler.service로 실행한다. 각각의 스케줄러는 각각의 kube-scheduler.service 파일을 가지고 이는 고유한 이름을 갖는다.
// my-scheduler-config.yaml
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
추가적인 스케줄러를 파드로 배포하는 방법
파드 yaml의 spec.containers 하위에 아래와 같이 작성한다.
//my-custom-scheduler.yaml
apiVersion: Pod
metadata:
name: my-custom-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --config=/etc/kubernetes/my-scheduler-config.yaml
image: k8s.gcr.io/kube-scheduler-amd64:v1.11.3
name: kube-scheduler
동일한 스케줄러의 복사본이 여러 개의 master node에서 필요하면 한 번에 하나씩만 활성화될 수 있기 때문에 leaderElection을 설정한다.
//my-scheduler-config.yaml
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- scheduerName: my-scheduler
leaderElection:
leaderElect: true
resourceNamespace: kube-system
resourceName: lock-object-my-scheduler
파드에서 다른 스케줄러를 사용하는 방법
yaml 파일의 spec 하위에 schedulerName을 명시한다.
스케줄러 확인하는 방법
kubectl get pods --namespace=kube-system
사용자 지정 스케줄러 사용하는 방법
schedulerName만 잘 명시해주면 된다!
//pod-definition.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
schedulerName: my-custom-scheduler그런 다음 kubectl create -f pod-definition.yaml 명령으로 파드를 생성해주고, kubectl get pods로 파드가 running 상태인지 확인한다. 스케줄러가 제대로 작동되지 않으면 파드는 pending으로 남는다.
스케줄러 사용 여부 확인
- kubectl get events -o wide
- kubectl logs my-custom-scheduler --name-space=kube-system
실습
1) k get pods -n kube-system || k get pods -A
2) k describe pod kube-scheduler-controlplane -n kube-system
3) k get sa my-scheduler -n kube-system
4) k create configmap my-scheduler-config --from-file=/root/my-scheduler-config.yaml -n kube-system && k get configmap my-scheduler-config -n kube-system
5) k descibe pod kube-scheduler-controlplane -n kube-sytem | grep Image && vi my-scheduler.yaml 해서 image에 나온 값 넣고 저장 && k create -f my-scheduler.yaml
6) vi nginx-pod.yaml && schedulerName 필드 생성해서 my-custom-scheduler 작성 && k create -f nginx-pod.yaml
Scheduler Profile
스케줄링 프로파일 설정하는 방법
1. [scheduling queue] 스케줄링을 기다리는 파드들은 scheduling queue에 위치된다.
- 이때 정의된 우선순위에 따라 파드들이 스케줄링됨
- spec.priorityClassName 필드를 사용해 만들어 놓은 우선순위 클래스 yaml 파일의 이름을 작성해서 우선순위를 정함
2. [filtering] 사용할 수 있는 노드들을 필터링
3. [scoring] 점수 매기기
- 남는 공간을 기반으로 어떤 노드가 더 유리한지 점수를 매김
4. [binding] 연결
- 파드와 노드 연결
스케줄링 플러그인
프로파일 성정은 플러그인에서 이뤄지고, 프로파일 단계마다 사용하는 플러그인이 다르다.
1. Scheduling Queue: PrioritySort
2. Filtering: NodeResourceFit, NodeName, NodeUnschedulable
3. Scoring: NodeResourceFit, ImageLocality
4. Binding: DefaultBinder
Extension Points: 플러그인이 붙을 수 있는 곳으로 이를 통해서 플러그인을 새로 정의하고 사용할 수 있음
(예) queueSort, preFilter, filter, postFilter, preScore, score, reserve, premit, preBind, bind, postBind
스케줄러 프로파일
하나의 yaml 파일에 여러 개의 프로파일을 관리할 수 있다.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler-2
plugins:
score:
disabled:
- name: TaintToleration
enabled:
- name: MyCustomPluginA
- name: MyCustomPluginB
- schedulerName: my-scheduler-3
plugins:
preScore:
disabled:
- name: '*'
enabled:
- name: '*'